This example comes from Google’s cookbook and extracts structured data from a PDF invoice. The goal is to extract the invoice number, date, and all list items with description, quantity, and gross worth, as well as the total gross worth.
import chatlas as ctlfrom pydantic import BaseModel, Fieldclass Item(BaseModel): description: str= Field(description="The description of the item") quantity: float= Field(description="The Qty of the item") gross_worth: float= Field(description="The gross worth of the item")class Invoice(BaseModel):"""Extract the invoice number, date and all list items with description, quantity and gross worth and the total gross worth.""" invoice_number: str= Field(description="The invoice number e.g. 1234567890") date: str= Field(description="The date of the invoice e.g. 10/09/2012") items: list[Item] = Field( description="The list of items with description, quantity and gross worth" ) total_gross_worth: float= Field(description="The total gross worth of the invoice")_ = Invoice.model_rebuild()chat = ctl.ChatOpenAI()res = chat.chat_structured("https://storage.googleapis.com/generativeai-downloads/data/pdf_structured_outputs/invoice.pdf", data_model=Invoice,)res.model_dump_json(indent=2)
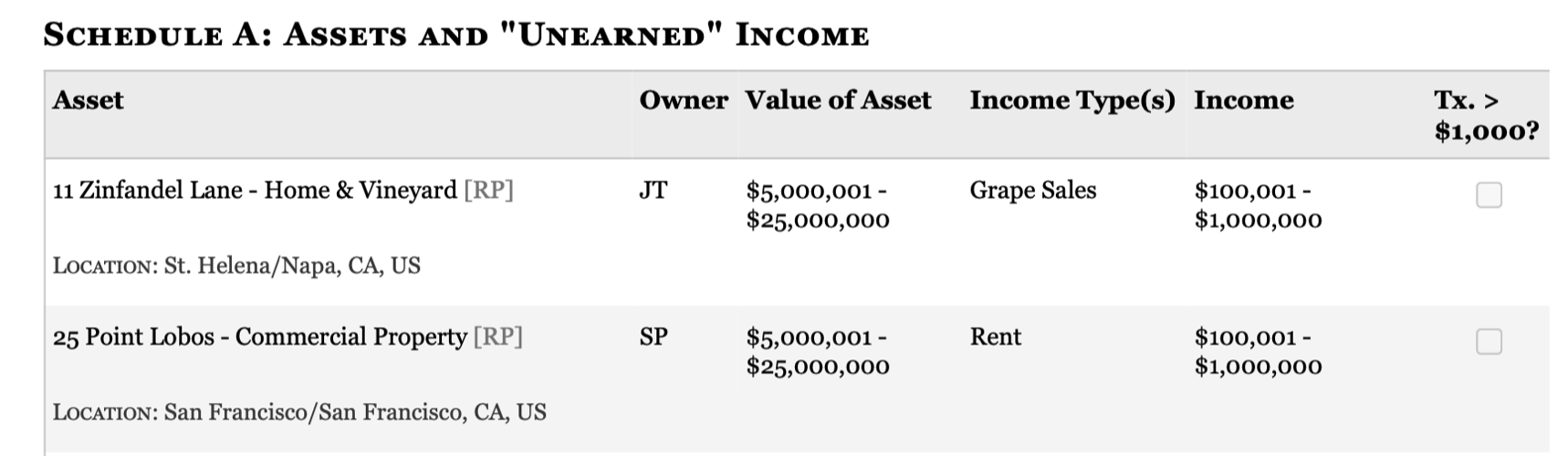
This example comes from Dan Nguyen (you can see other interesting applications at that link). The goal is to extract structured data from this screenshot:
Screenshot of schedule A: a table showing assets and “unearned” income
Even without any descriptions, ChatGPT does pretty well:
import chatlas as ctlfrom pydantic import BaseModel, Fieldimport pandas as pdclass Asset(BaseModel): assert_name: str owner: str location: str asset_value_low: int asset_value_high: int income_type: str income_low: int income_high: int tx_gt_1000: boolclass DisclosureReport(BaseModel): assets: list[Asset]chat = ctl.ChatOpenAI()data = chat.chat_structured( ctl.content_image_file("../images/congressional-assets.png"), data_model=DisclosureReport,)pd.DataFrame([c.model_dump() for c in data.assets])