import json
import pandas as pd
from chatlas import ChatOpenAI
from pydantic import BaseModel, FieldStructured data
When using an LLM to extract data from text or images, you can ask the chatbot to nicely format it, in JSON or any other format that you like. This will generally work well most of the time, but there’s no guarantee that you’ll actually get the exact format that you want. In particular, if you’re trying to get JSON, find that it’s typically surrounded in ```json, and you’ll occassionally get text that isn’t actually valid JSON. To avoid these challenges you can use a recent LLM feature: structured data (aka structured output). With structured data, you supply a type specification that exactly defines the object structure that you want and the LLM will guarantee that’s what you get back.
Structured data basics
To extract structured data you call the .extract_data() method instead of the .chat() method. You’ll also need to define a type specification that describes the structure of the data that you want (more on that shortly). Here’s a simple example that extracts two specific values from a string:
class Person(BaseModel):
name: str
age: int
chat = ChatOpenAI()
chat.extract_data(
"My name is Susan and I'm 13 years old",
data_model=Person,
){'name': 'Susan', 'age': 13}The same basic idea works with images too:
from chatlas import content_image_url
class Image(BaseModel):
primary_shape: str
primary_colour: str
chat.extract_data(
content_image_url("https://www.r-project.org/Rlogo.png"),
data_model=Image,
){'primary_shape': 'letter and circle', 'primary_colour': 'blue and gray'}Data types basics
To define your desired type specification (also known as a schema), you use a pydantic model.
In addition to the model definition with field names and types, you may also want to provide the LLM with an additional context about what each field/model represents. In this case, include a Field(description="...") for each field, and a docstring for each model. This is a good place to ask nicely for other attributes you’ll like the value to have (e.g. minimum or maximum values, date formats, …). There’s no guarantee that these requests will be honoured, but the LLM will usually make a best effort to do so.
class Person(BaseModel):
"""A person"""
name: str = Field(description="Name")
age: int = Field(description="Age, in years")
hobbies: list[str] = Field(
description="List of hobbies. Should be exclusive and brief."
)Now we’ll dive into some examples before coming back to talk more data types details.
Examples
The following examples, which closely inspired by the Claude documentation, hint at some of the ways you can use structured data extraction.
Example 1: Article summarisation
with open("examples/third-party-testing.txt") as f:
text = f.read()
class ArticleSummary(BaseModel):
"""Summary of the article."""
author: str = Field(description="Name of the article author")
topics: list[str] = Field(
description="Array of topics, e.g. ['tech', 'politics']. Should be as specific as possible, and can overlap."
)
summary: str = Field(description="Summary of the article. One or two paragraphs max")
coherence: int = Field(
description="Coherence of the article's key points, 0-100 (inclusive)"
)
persuasion: float = Field(
description="Article's persuasion score, 0.0-1.0 (inclusive)"
)
chat = ChatOpenAI()
data = chat.extract_data(text, data_model=ArticleSummary)
print(json.dumps(data, indent=2)){
"author": "Anthropic",
"topics": [
"AI policy",
"third-party testing",
"AI safety",
"regulatory framework",
"open-source AI"
],
"summary": "This article argues for the necessity of third-party testing in the AI sector to mitigate potential risks associated with frontier AI systems. It emphasizes developing a comprehensive testing regime, involving collaboration between industry, government, and academia, to ensure AI technologies are safe and free from misuse. The article describes how such testing could prevent societal harm while fostering trust in AI systems. Anthropic outlines its policy priorities and initiatives in line with these goals, stressing the need for effective evaluation systems and national security measures to address the challenges posed by increasingly capable AI models.",
"coherence": 85,
"persuasion": 0.75
}Example 2: Named entity recognition
text = "John works at Google in New York. He met with Sarah, the CEO of Acme Inc., last week in San Francisco."
class NamedEntity(BaseModel):
"""Named entity in the text."""
name: str = Field(description="The extracted entity name")
type_: str = Field(description="The entity type, e.g. 'person', 'location', 'organization'")
context: str = Field(description="The context in which the entity appears in the text.")
class NamedEntities(BaseModel):
"""Named entities in the text."""
entities: list[NamedEntity] = Field(description="Array of named entities")
chat = ChatOpenAI()
data = chat.extract_data(text, data_model=NamedEntities)
pd.DataFrame(data["entities"])| name | type_ | context | |
|---|---|---|---|
| 0 | John | person | Subject of the sentence, works at Google in Ne... |
| 1 | organization | Employer of John, located in New York | |
| 2 | New York | location | Location where John works |
| 3 | Sarah | person | Met with John last week in San Francisco |
| 4 | CEO | title | Title of Sarah, she is the CEO of Acme Inc. |
| 5 | Acme Inc. | organization | Sarah is the CEO of Acme Inc. |
| 6 | San Francisco | location | Location where John met with Sarah |
Example 3: Sentiment analysis
text = "The product was okay, but the customer service was terrible. I probably won't buy from them again."
class Sentiment(BaseModel):
"""Extract the sentiment scores of a given text. Sentiment scores should sum to 1."""
positive_score: float = Field(
description="Positive sentiment score, ranging from 0.0 to 1.0"
)
negative_score: float = Field(
description="Negative sentiment score, ranging from 0.0 to 1.0"
)
neutral_score: float = Field(
description="Neutral sentiment score, ranging from 0.0 to 1.0"
)
chat = ChatOpenAI()
chat.extract_data(text, data_model=Sentiment){'positive_score': 0.1, 'negative_score': 0.7, 'neutral_score': 0.2}Note that while we’ve asked nicely for the scores to sum 1, which they do in this example (at least when I ran the code), this is not guaranteed.
Example 4: Text classification
from typing import Literal
text = "The new quantum computing breakthrough could revolutionize the tech industry."
class Classification(BaseModel):
name: Literal[
"Politics", "Sports", "Technology", "Entertainment", "Business", "Other"
] = Field(description="The category name")
score: float = Field(description="The classification score for the category, ranging from 0.0 to 1.0.")
class Classifications(BaseModel):
"""Array of classification results. The scores should sum to 1."""
classifications: list[Classification]
chat = ChatOpenAI()
data = chat.extract_data(text, data_model=Classifications)
pd.DataFrame(data["classifications"])| name | score | |
|---|---|---|
| 0 | Technology | 0.85 |
| 1 | Business | 0.10 |
| 2 | Other | 0.05 |
Example 5: Working with unknown keys
from chatlas import ChatAnthropic
class Characteristics(BaseModel, extra="allow"):
"""All characteristics"""
pass
prompt = """
Given a description of a character, your task is to extract all the characteristics of that character.
<description>
The man is tall, with a beard and a scar on his left cheek. He has a deep voice and wears a black leather jacket.
</description>
"""
chat = ChatAnthropic()
data = chat.extract_data(prompt, data_model=Characteristics)
print(json.dumps(data, indent=2)){
"height": "tall",
"facial_features": [
"beard",
"scar on left cheek"
],
"voice": "deep",
"clothing": [
"black leather jacket"
]
}This example only works with Claude, not GPT or Gemini, because only Claude supports adding arbitrary additional properties.
Example 6: Extracting data from an image
The final example comes from Dan Nguyen (you can see other interesting applications at that link). The goal is to extract structured data from this screenshot:
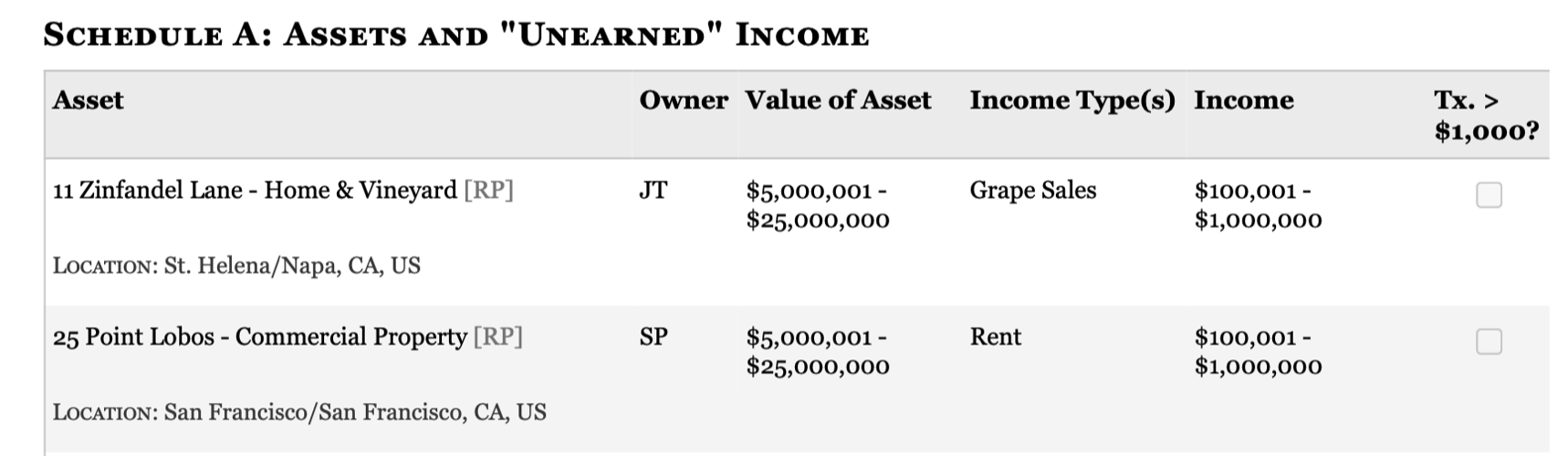
Even without any descriptions, ChatGPT does pretty well:
from chatlas import content_image_file
class Asset(BaseModel):
assert_name: str
owner: str
location: str
asset_value_low: int
asset_value_high: int
income_type: str
income_low: int
income_high: int
tx_gt_1000: bool
class DisclosureReport(BaseModel):
assets: list[Asset]
chat = ChatOpenAI()
data = chat.extract_data(
content_image_file("images/congressional-assets.png"), data_model=DisclosureReport
)
pd.DataFrame(data["assets"])| assert_name | owner | location | asset_value_low | asset_value_high | income_type | income_low | income_high | tx_gt_1000 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 11 Zinfandel Lane - Home & Vineyard [RP] | JT | St. Helena/Napa, CA, US | 5000001 | 25000000 | Grape Sales | 100001 | 1000000 | True |
| 1 | 25 Point Lobos - Commercial Property [RP] | SP | San Francisco/San Francisco, CA, US | 5000001 | 25000000 | Rent | 100001 | 1000000 | False |
Advanced data types
Now that you’ve seen a few examples, it’s time to get into more specifics about data type declarations.
Required vs optional
By default, model fields are in a sense “required”, unless None is allowed in their type definition. Including None is a good idea if there’s any possibility of the input not containing the required fields as LLMs may hallucinate data in order to fulfill your spec.
For example, here the LLM hallucinates a date even though there isn’t one in the text:
class ArticleSpec(BaseModel):
"""Information about an article written in markdown"""
title: str = Field(description="Article title")
author: str = Field(description="Name of the author")
date: str = Field(description="Date written in YYYY-MM-DD format.")
prompt = """
Extract data from the following text:
<text>
# Structured Data
By Hadley Wickham
When using an LLM to extract data from text or images, you can ask the chatbot to nicely format it, in JSON or any other format that you like.
</text>
"""
chat = ChatOpenAI()
data = chat.extract_data(prompt, data_model=ArticleSpec)
print(json.dumps(data, indent=2)){
"title": "Structured Data",
"author": "Hadley Wickham",
"date": "2023-10-21"
}Note that I’ve used more of an explict prompt here. For this example, I found that this generated better results and that it’s a useful place to put additional instructions.
If I let the LLM know that the fields are all optional, it’ll return None for the missing fields:
class ArticleSpec(BaseModel):
"""Information about an article written in markdown"""
title: str = Field(description="Article title")
author: str = Field(description="Name of the author")
date: str | None = Field(description="Date written in YYYY-MM-DD format.")
data = chat.extract_data(prompt, data_model=ArticleSpec)
print(json.dumps(data, indent=2)){
"title": "Structured Data",
"author": "Hadley Wickham",
"date": null
}Data frames
If you want to define a data frame like data_model, you might be tempted to create a model like this, where each field is a list of scalar values:
class Persons(BaseModel):
name: list[str]
age: list[int]This however, is not quite right because there’s no way to specify that each field should have the same length. Instead you need to turn the data structure “inside out”, and instead create an array of objects:
class Person(BaseModel):
name: str
age: int
class Persons(BaseModel):
persons: list[Person]If you’re familiar with the terms between row-oriented and column-oriented data frames, this is the same idea.
Token usage
Below is a summary of the tokens used to create the output in this example.
from chatlas import token_usage
token_usage()[{'name': 'OpenAI', 'input': 6081, 'output': 583},
{'name': 'Anthropic', 'input': 463, 'output': 81}]